Softeq unterstützte ein großes US-amerikanisches Telekommunikationsunternehmen bei der Entwicklung einer maßgeschneiderten Media-Streaming-Lösung für Digital Signage. Die Lösung ermöglicht es Einzelhändlern und Agenturen, Werbeinhalte auf digitale Displays an öffentlichen Orten zu übertragen.
Zu den funktionalen Komponenten des Systems gehören
- USB-Stick-ähnliche Geräte mit einer speziellen Android-Firmware,
- ein webbasiertes Admin-Portal, über das man Medieninhalte hochladen, Geräte einrichten, Marketing-Kampagnen verwalten und Berichte erstellen kann,
- mobile Apps, die teilweise die Funktionalität des Admin-Portals widerspiegeln und den Nutzern helfen, die Ausgabe von Medieninhalten zu kontrollieren,
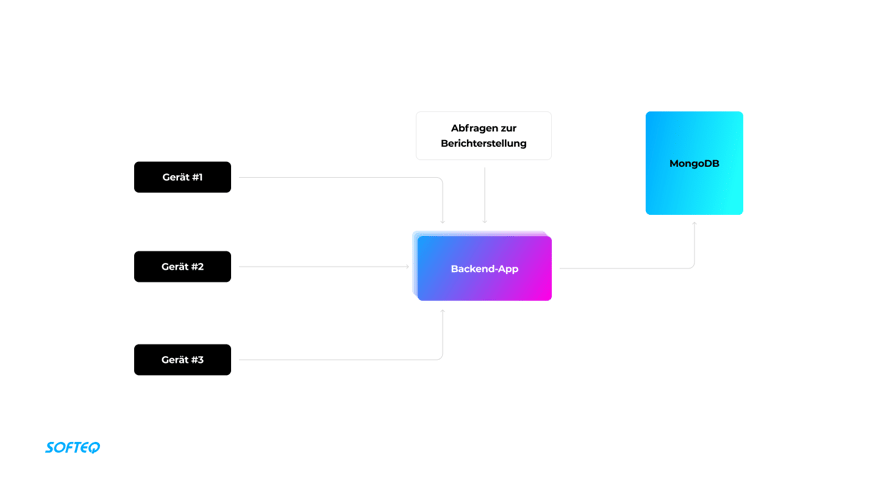
- ein sicheres Backend, das die Geschäftslogik des Systems unterstützt: Datenspeicherung, Lokalisierung der Geräte (GPS), Verwaltung der Benutzerrollen, Remote Support usw.
Neben der Verbreitung digitaler Inhalte hilft das System bei der Auswertung der Kampagnenleistung. Dafür sammeln die Gadgets Daten zu Ad Impressions für bestimmte Kampagnen und Inhaltstypen und senden die Daten jede Stunde an das Backend. Eine Werbeagentur kann die Daten zur Kampagnenleistung über einen bestimmten Zeitraum abfragen und die Daten über das Admin-Portal einsehen.
Technische Herausforderung
Zum Speichern der Daten wählten wir zunächst MongoDB, das für jede Datei eine eindeutige ID erstellt und die Dokumente in einer Tabelle anordnet. Mithilfe der MongoDB Aggregation Pipeline implementierten wir auch eine Funktion zur Erstellung von Berichten. Die Lösung funktionierte gut, bis die Datenbank auf 20 Millionen Datensätze anwuchs.
Danach traten folgende Schwierigkeiten auf:
- Die Erfassung der Daten verlangsamte sich erheblich.
- Das System verteilte die Nutzeranfragen nicht mehr auf mehrere Server, wodurch sich die Reaktionszeit des Servers erhöhte.
- Nach einer Nutzeranfrage musste das System alle vorhandenen Daten laden, anstatt die Daten von bestimmten Spalten abzurufen.
- Bei langen Aggregationen ging den MongoDB-Replikaten der Speicher aus.
Diese Probleme beeinträchtigten die Leistung des Systems. Um sie zu lösen, unternahm unser Team Folgendes:
- Tägliches Voraggregieren von Leistungsdaten der Anzeigen. Mit diesem Ansatz konnten wir das Datenvolumen um bis zu 800 % reduzieren und die Zeit für die Berichtserstellung deutlich verkürzen.
- Implementieren von Covering Indexes. Ein Covering Index enthält alle in einer Abfrage erwähnten Daten – der Server muss die Daten nicht aus der Haupttabelle abrufen, um Leistungsberichte zu generieren.
Mit diesen Optimierungen gelang es uns, die Leistung des Systems zu stabilisieren. Zur Unterstützung der wachsenden Anzahl von Geräten, mussten wir dann jedoch die Backend-Kapazität skalieren. Um die Abfragegeschwindigkeit zu optimieren, benötigten wir eine Backend-Lösung, die noch skalierbarer war.
Wechsel des Tech-Stacks, um IoT-Analysen zu beschleunigen
Aufgrund einiger technischer Einschränkungen kann MongoDB Aggregationsabfragen nicht effizient verarbeiten:
- Non-clustered Index. MongoDB verwendet einen B-Baum-Index. Er ist nicht selektiv: Die Datenbank muss alle darin gespeicherten Dokumente lesen, um die vom Nutzer benötigten Informationen zu finden.
- Datenspeicherung nach Zeilen. Um einen Leistungsbericht für Anzeigen zu erstellen, muss das Backend die Daten aus allen Spalten der Datenbanktabelle laden.
- MongoDB unterstützt keine Datenkomprimierung. Datenkomprimierung hilft, die Größe einer Datenbank zu reduzieren und I/O-intensive Workloads zu verbessern (da die Daten auf weniger Seiten gespeichert sind und Abfragen weniger Seiten von der Festplatte lesen müssen).
Um MongoDB zu ersetzen, machten wir uns auf die Suche nach einer Backend-Lösung mit der wir diese Einschränkungen überwinden könnten.
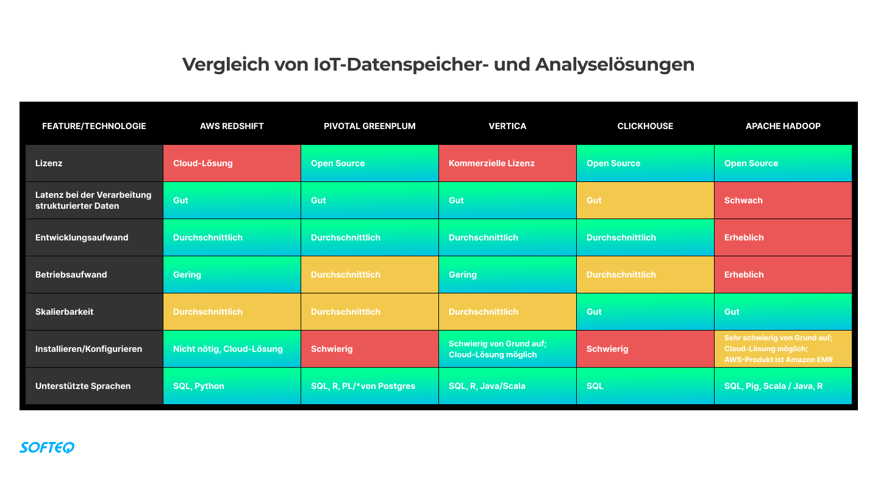
Schließlich entschieden wir uns für AWS Redshift – einen vollständig verwalteten Data-Warehouse-Service mit Datenvolumen in Petabyte-Größe in der Cloud. Der Service ist kosteneffizient, stabil und DevOps-freundlich.
Die wichtigsten Vorteile:
- AWS Redshift ermöglicht es Entwicklern, in wenigen Stunden weitere Rechenknoten zur Datenbank hinzuzufügen.
- Im Unterschied zu zeilenorientierten Datenbanken kann AWS Redshift – als spaltenorientierte Datenbank – Abfragen schneller verarbeiten und Analysen durchführen.
- Es basiert auf pgSQL, daher musste die IT-Abteilung unseres Kunden keine neue Programmiersprache erlernen.
- AWS Redshift verwendet Clustered Indexes anstelle eines B-Baums und kann Millionen von Tabellenzeilen ohne zusätzliche Datenstruktur filtern.
- AWS automatisiert den Clusterbetrieb. Dies vereinfacht Konfiguration und Einsatz.
- AWS Redshift ist ein Data-Warehouse-Service für das gesamte System.
- Das Service Level Agreement (SLA) liegt bei 99,9 %.

AWS Redshift im Überblick
Ein AWS Redshift-Cluster enthält einen einzelnen Leader-Knoten, der Datenabfragen verarbeitet und Aufgaben auf Rechenknoten verteilt. Nachdem die Rechenknoten ihre Aufgaben abgeschlossen haben, fasst der Leader-Knoten die Ergebnisse zusammen und sendet die Daten an den Client. Redshift bietet Sortierschlüssel anstelle eines B-Baums. Dies hilft dabei, Suchkriterien zu präzisieren, Daten zu komprimieren und somit den Speicherplatz zu optimieren. Außerdem werden Informationen in Spalten und nicht in Zeilen gespeichert.
Zudem ist AWS Redshift mit der Lösung zur Datenspeicherung AWS S3 integriert. So können wir JSON-Daten aus MongoDB einfach in JSON-Dateien übertragen, sie in S3 hochladen und die Informationen aus S3 in AWS Redshift importieren. Auf die gleiche Weise können wir stillgelegte Daten nach einer bestimmten Zeit in S3 hochladen.
Ergebnisse
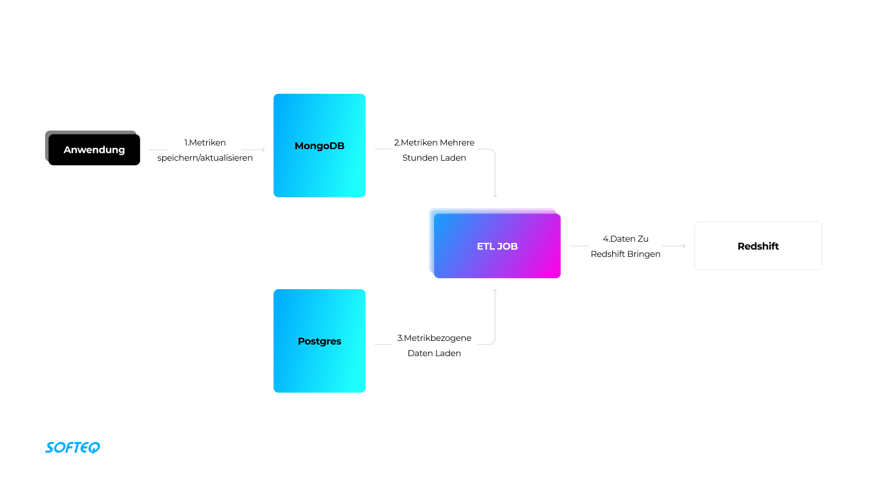
Die Media-Streaming-Lösung verwendet MongoDB zur Verarbeitung von Messdaten zur Anzeigen-Performance. ETL-Jobs übernehmen das Batch Loading der Kennzahlen von MongoDB/Postgres nach Redshift. Dank der Spalte modified_date_time wissen wir, wann die Daten geändert wurden. Um die ETL-Jobs zu implementieren, verwendeten wir Spring Boot mit dem Redshift JDBC-Treiber. Um Berichte zu erstellen, generiert die Anwendung Anfragen und sendet diese über den Redshift JDBC-Treiber direkt an Redshift.
 Als wir unsere Lösung testeten, stellten wir außerdem fest, dass die maximal mögliche Anzahl der gespeicherten Daten für einen Cluster mit zwei Knoten 2 Milliarden Datensätze beträgt (für unseren Use Case). In diesem Fall bräuchte das System etwa fünf Minuten, um einen Bericht zu erstellen.
Als wir unsere Lösung testeten, stellten wir außerdem fest, dass die maximal mögliche Anzahl der gespeicherten Daten für einen Cluster mit zwei Knoten 2 Milliarden Datensätze beträgt (für unseren Use Case). In diesem Fall bräuchte das System etwa fünf Minuten, um einen Bericht zu erstellen.
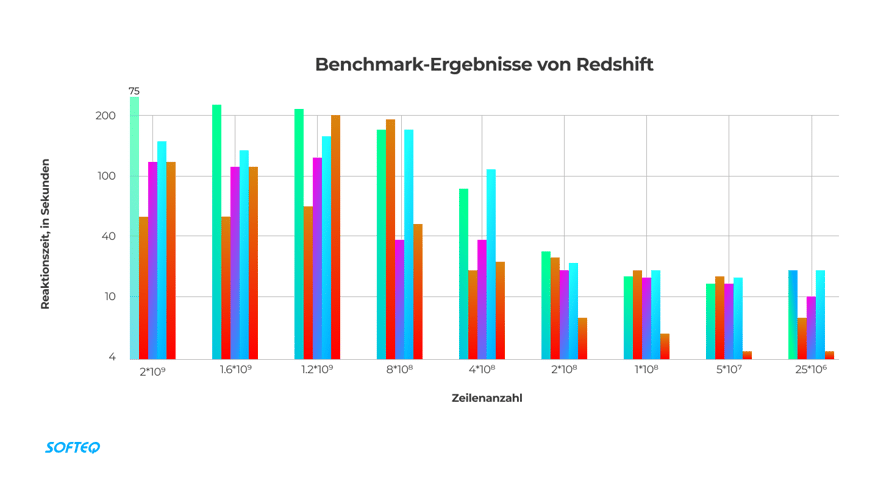 Um die Leistung von MongoDB und Redshift zu vergleichen, führen wir das Beispiel einer Datenbank an, die 25 Millionen Datensätze enthält. MongoDB braucht 12 Minuten, um nach der Anfrage eines Nutzers einen Bericht zu erstellen. AWS Redshift hingegen erledigt diese Aufgabe in etwa 20 Sekunden. So können wir die gleiche Datenverarbeitung und -analyse 36 Mal schneller durchführen.
Um die Leistung von MongoDB und Redshift zu vergleichen, führen wir das Beispiel einer Datenbank an, die 25 Millionen Datensätze enthält. MongoDB braucht 12 Minuten, um nach der Anfrage eines Nutzers einen Bericht zu erstellen. AWS Redshift hingegen erledigt diese Aufgabe in etwa 20 Sekunden. So können wir die gleiche Datenverarbeitung und -analyse 36 Mal schneller durchführen.